Reflections from KDD 2023
Last week was quite busy for me. It was my first time attending and presenting at KDD. 29th ACM SIGKDD (Special Interest Group on Knowledge Discovery and Data Mining) is ACM (Association for Computing Machinery)’s influential conference on machine learning, AI and everything in between. It is one of the most popular conferences in the field of data mining in the world.
I also presented my research work on end-to-end inventory prediction and optimzation for use in guaranteed delivery advertising field. The work was done in collaboration with Alibaba and it is currently in production on their website. You can learn more about my presentation at https://www.harsh17.in/kdd2023/.
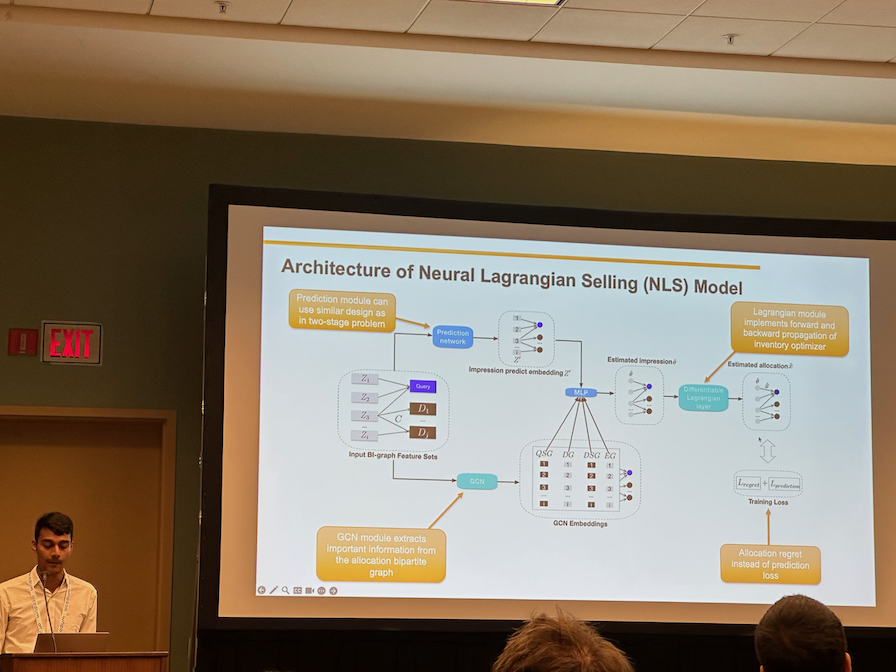


Below are my notes on the talks I attended
Full proceedings are at: https://kdd.org/kdd2023/wp-content/uploads/2023/08/toc.html
Keynotes
Jure Leskovec, SIGKDD Innovation Award Winner 2023
Jure Leskovec is a professor at Stanford and was the Chief Scientist at Pinterest. He was the winner of SIGKDD Innovation Award 2023.
Website: https://cs.stanford.edu/people/jure/
- Memetracker is an online tool that tracks the most mentioned phrase by analyzing 900,000 news stories and blog posts per day. It is available at http://snap.stanford.edu/memetracker/index.html
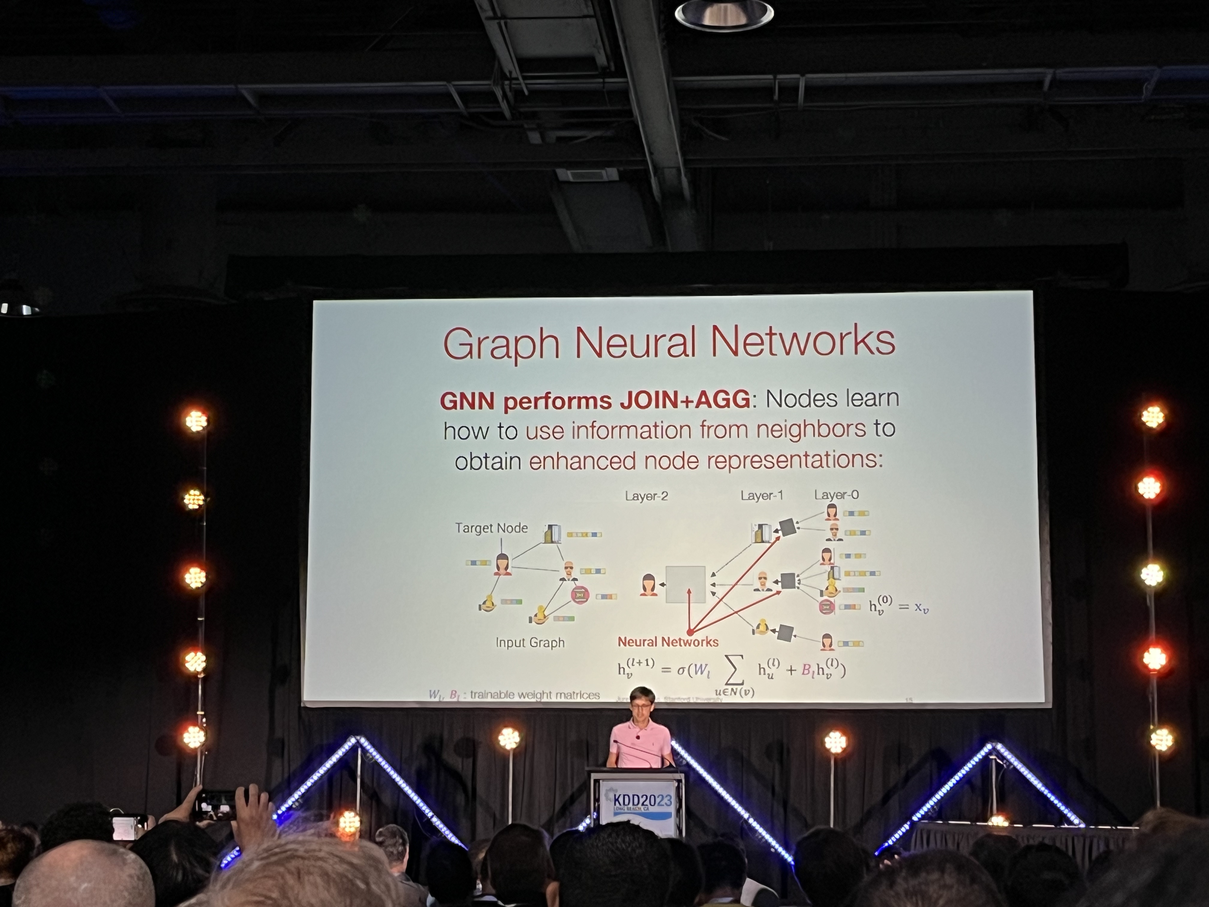
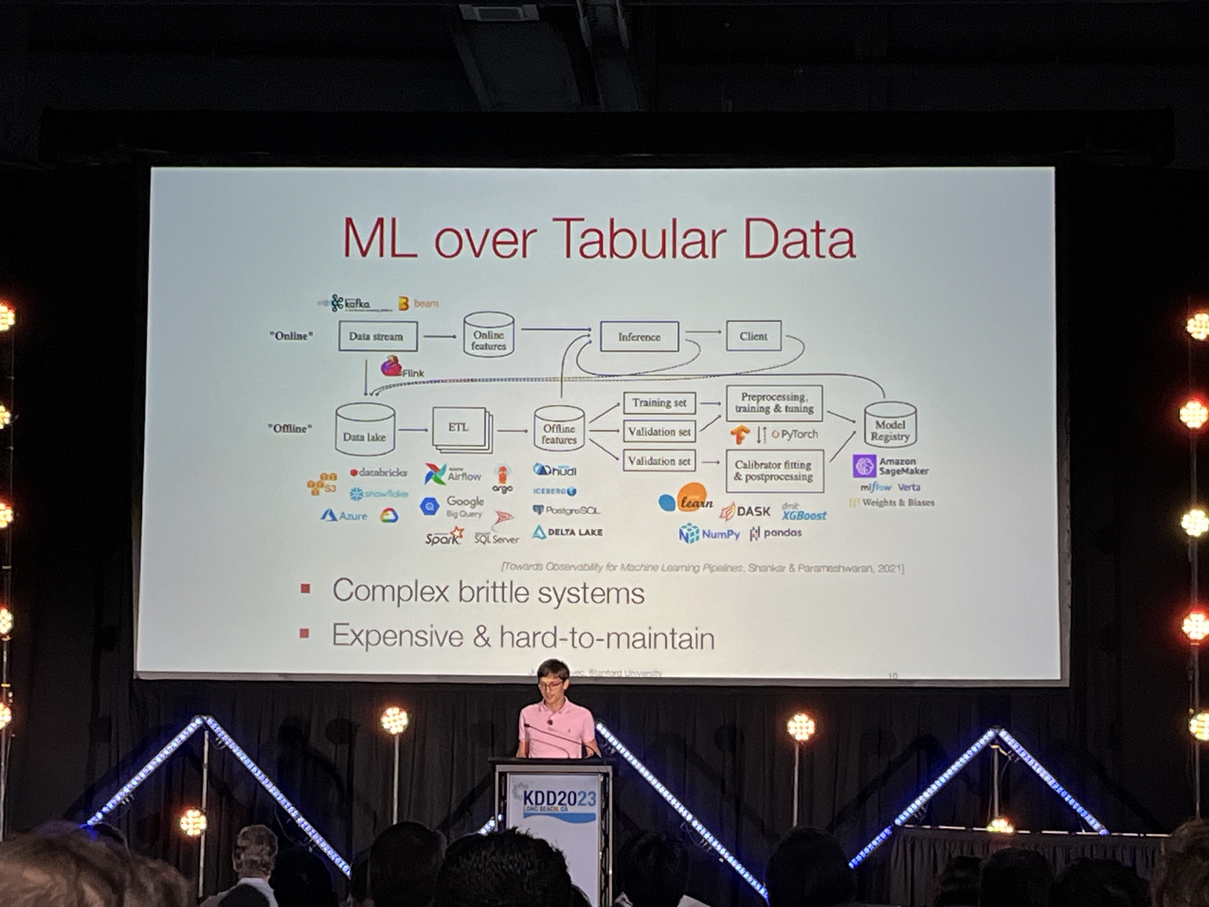
- Currently, our work involves use of tabular data. However, more natural state of data is graphs. Graphs showcase the relationships between different datasets and can also use information about the neighbours, that tabluar datasets cannot.
- We need a “transformer” for a database: something that fundamental that transforms how we do all data analysis; just the way transformers changed deep learning
- Graph neural networks learn information from neighbours to obtain enhanced node representations
- PyG from his team is the most widely used graph NN package


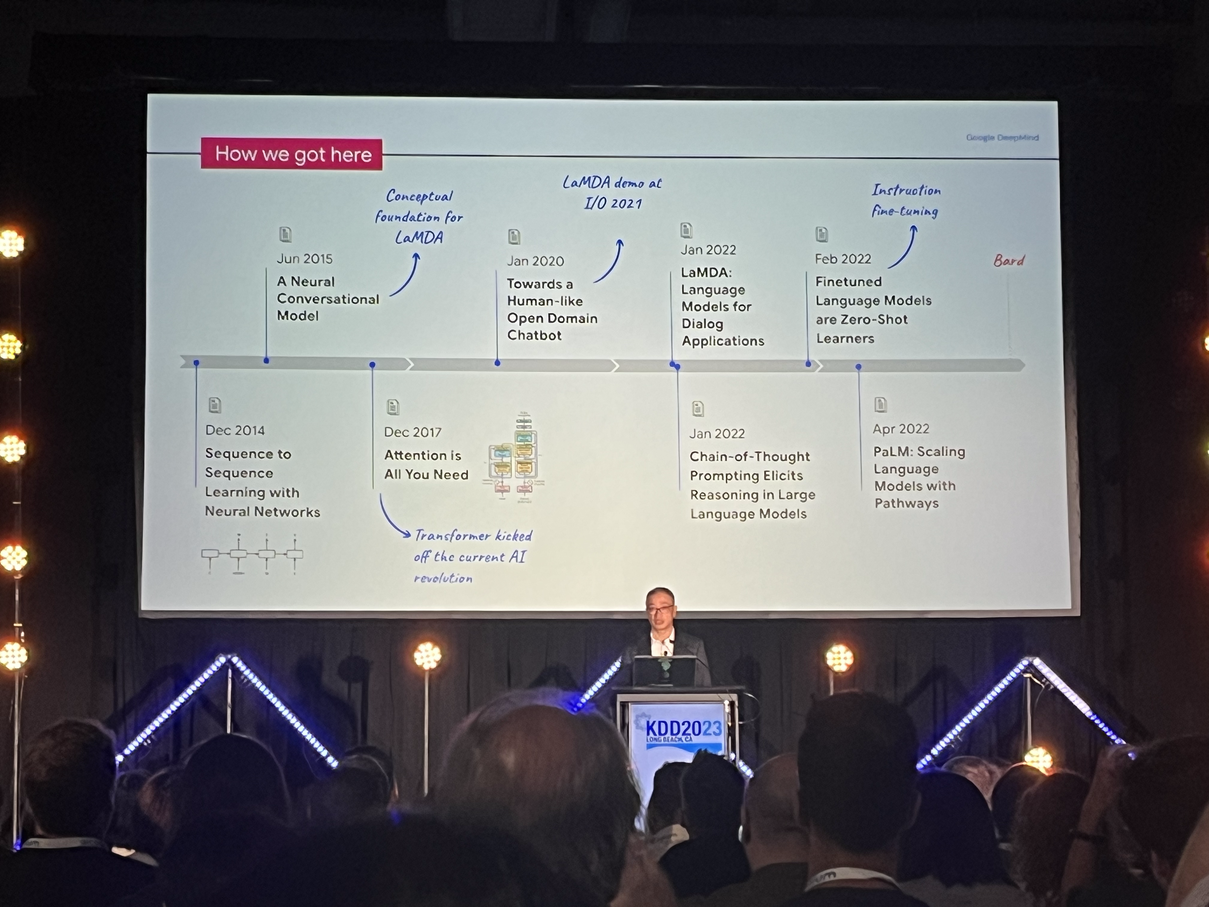
Ed Chi, Google (Keynote Day 1)
Ed H. Chi is a Distinguished Scientist at Google, leading several machine learning research teams focusing on neural modeling, reinforcement learning, dialog modeling, reliable/robust machine learning, and recommendation systems in Google Brain team.
Website: https://sites.google.com/view/edchi/
LLMs have raised the expectations on what we expect from ML and AI models
- 100 years ago, we couldn’t fly. Today, we are irritated if our flight is late by half an hour
Chain of thought prompting results in better model outputs than base model outputs
In simple terms, it means give examples of what you want from the model
Also called few-shot learning
Self-consistency Decoding
In critical tasks, ensemble model outputs into one output
Ask the same question several times, take the majority vote
Task decomposition
For complex tasks, decompose into smaller tasks. Either ask the model to break it down before attempting to solve it, or break it down yourself
Instruction tuning (prompt engineering) works better with more advanced models than simple models. In some small models, fine-tuning or better prompting results in no improvement at all
Evaluating outputs is critical
- Similar to how we had to deal with recommender system outputs







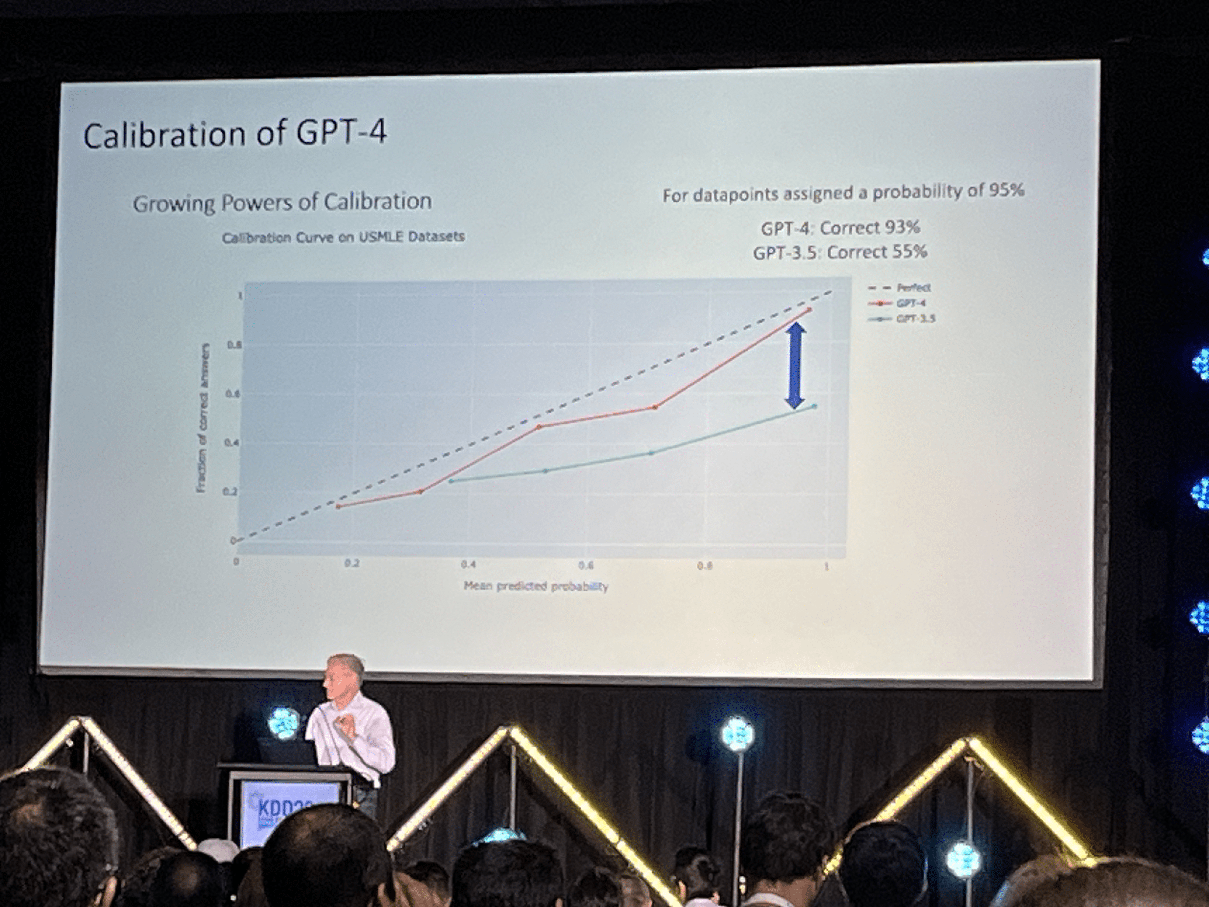
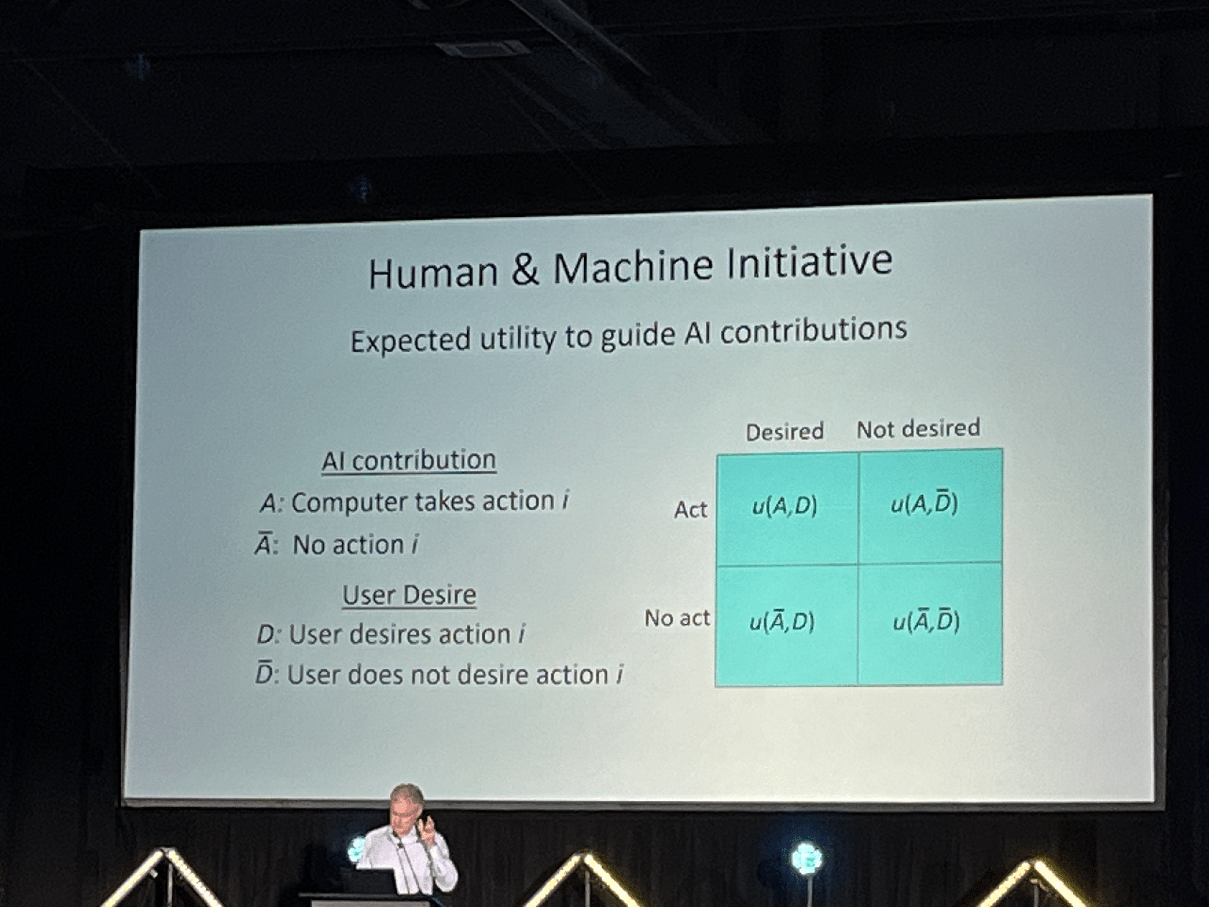
Eric Horowitz, Microsoft (Day 2 Keynote)
GPT performs better than most humans in medical licensing exams (almost perfect at 99.9%)
Medical error is the third largest cause of death in the US, after heart diseases and cancer (BMJ)
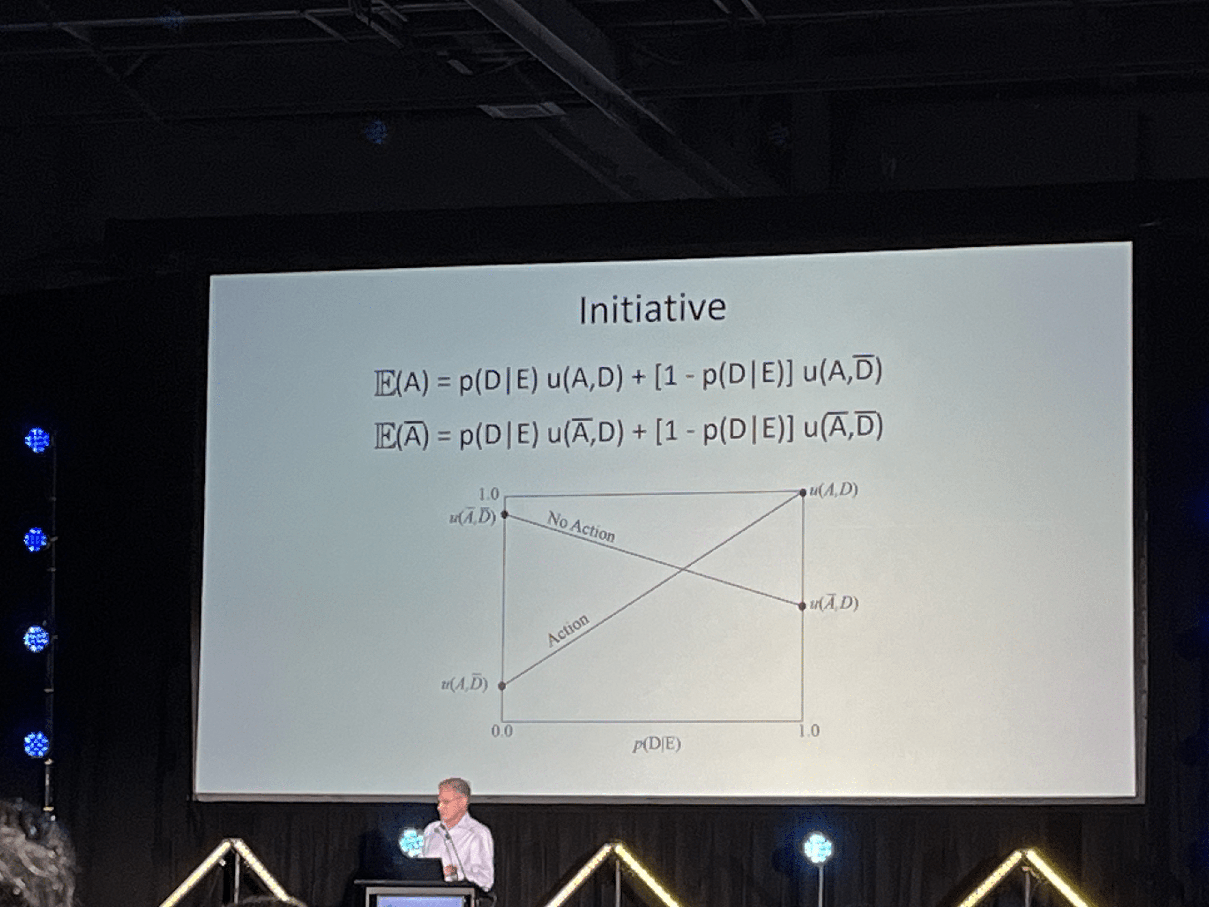
AI enables computation, which enables calculating the expected value of taking action or not taking an action
- Microsoft Teams: to minimise audio errors coming into a group call, predict when a person in a group call likely going to speak
P(Action | Information, AI-assistance) > P(Action | Info) or P(Action | AI-assistance)
Optimise for copilot
Areas where AI makes error; areas where humans make error
Combo of both leads to a better world
I asked the question: “What is a task that AI wouldn’t be able to do in five to ten years?”
Question: Five years ago, if you would have asked me if AI could sketch, I would laugh. Two years ago, if you would’ve asked if I can have an interesting argument with an AI, I would have said no. Today, I use it for coding, sketching and a lot more. A lot of “creative skills” can be done by AI. In fact, it performs better than most humans on creativity tests. What’s something that AI wouldn’t be able to do in ten years? Exclude jobs that we don’t want it to do: SC judges, caretakers, etc.”
Answer: There will be new jobs that’ll get created due to AI. It is difficult to say which jobs, exactly. (He said more but that’s the gist of it.)



Large Language Models Day
Jaime Teevan (Microsoft)
http://teevan.org/about/index.htm
Retrieval-based learning is private by design as only the relevant information is communicated via API to the LLM service provider
Rest of the document information is stored locally in a VectorDB of embeddings
These documents that have so far been isolated in corporate settings and accessible only to those “shared” parties can come together to be part of one database that all in the company can access
Like Google Maps, this forms a collaborative knowledge – one brain to feed it all, one source of truth, one access protocol (with several access levels)
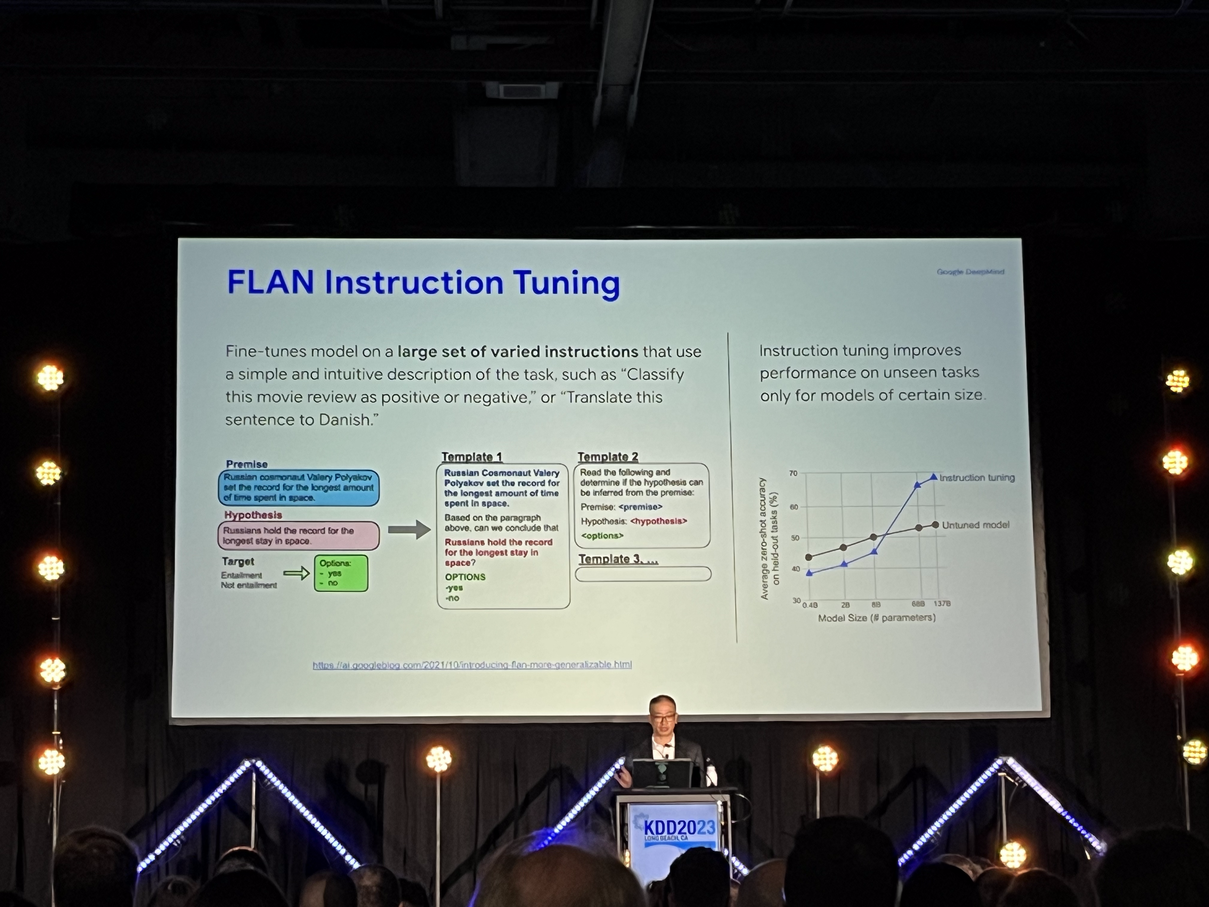
Denny Zhou (Google DeepMind)
Chain of thought prompting works better than one-shot or few-shot prompting in larger models
Giving specific examples of what you want as the output from the model is better than suggesting the kind of output you want
If you want it as a JSON file, say that
If you want it as a pd.DataFrame({…}), say that
If you want it as a markdown table, say that
BIG-Bench is Google’s evaluation tasks for LLMs
OpenAI’s evals: https://github.com/openai/evals
Vedanuj Goswami
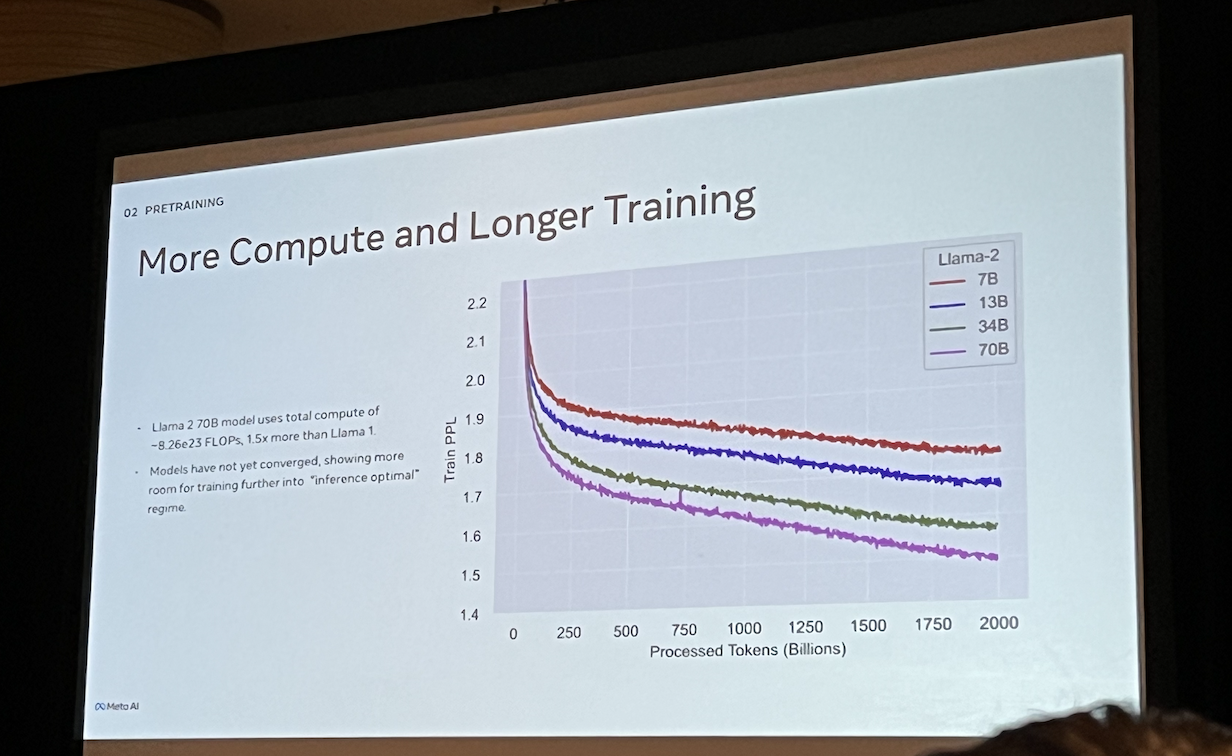
- Even with long training time and data, the models doesn’t show any sign of slowing down. More data and compute, keeps making these models better and better
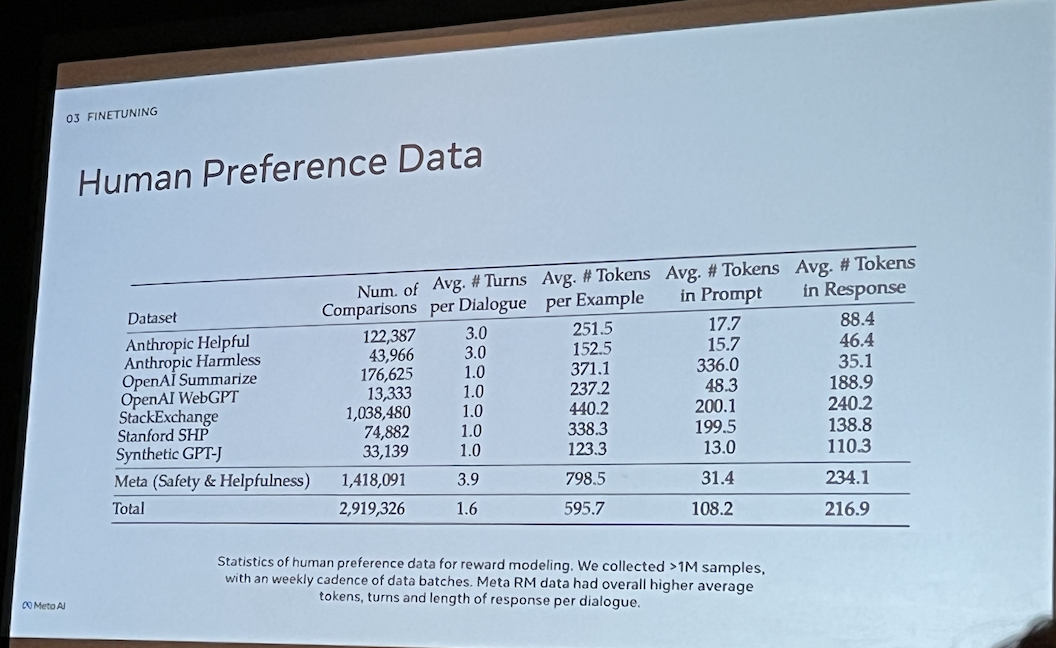
For fine-tuning the model (LLaMA 2), perform RLHF and Rejection Sampling
Weekly cadence in model output checks: RLHF, comparison between human and LLM output
In adversarial prompts, prefix with safety words to reduce their impact
In system prompt, feed in critical system values (corporate values, etc.)


Jason Wei (OpenAI)
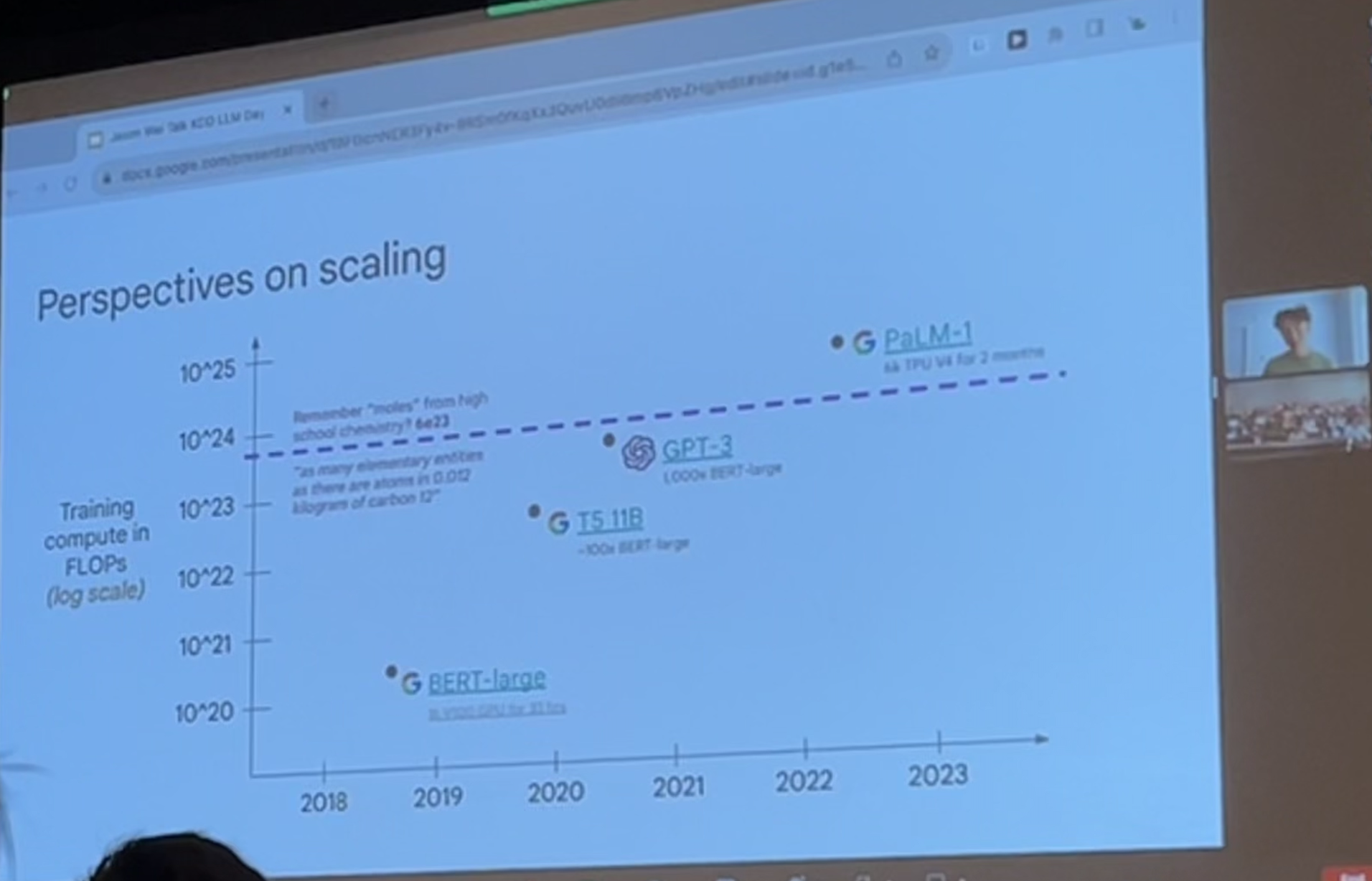
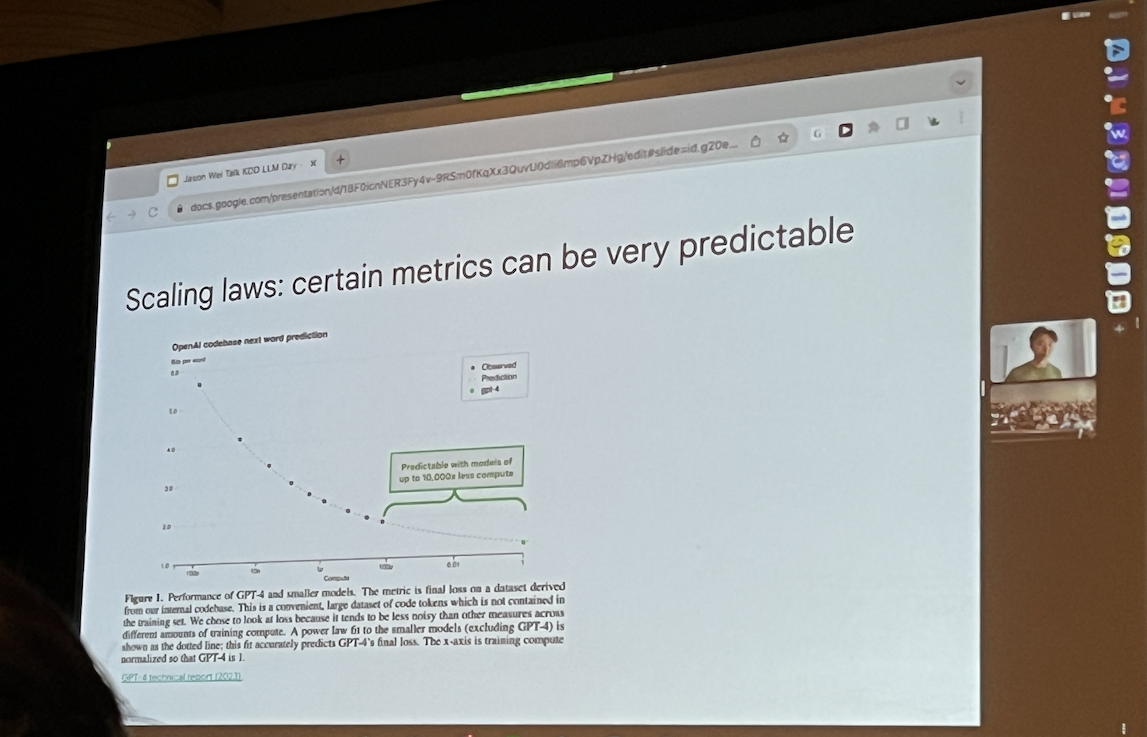
- Scaling Laws
- Tooling and infrastructure matter as more collaborators get together to work together
- Next word prediction is plateauing in performance, but there are emergent abilities (more on that later)
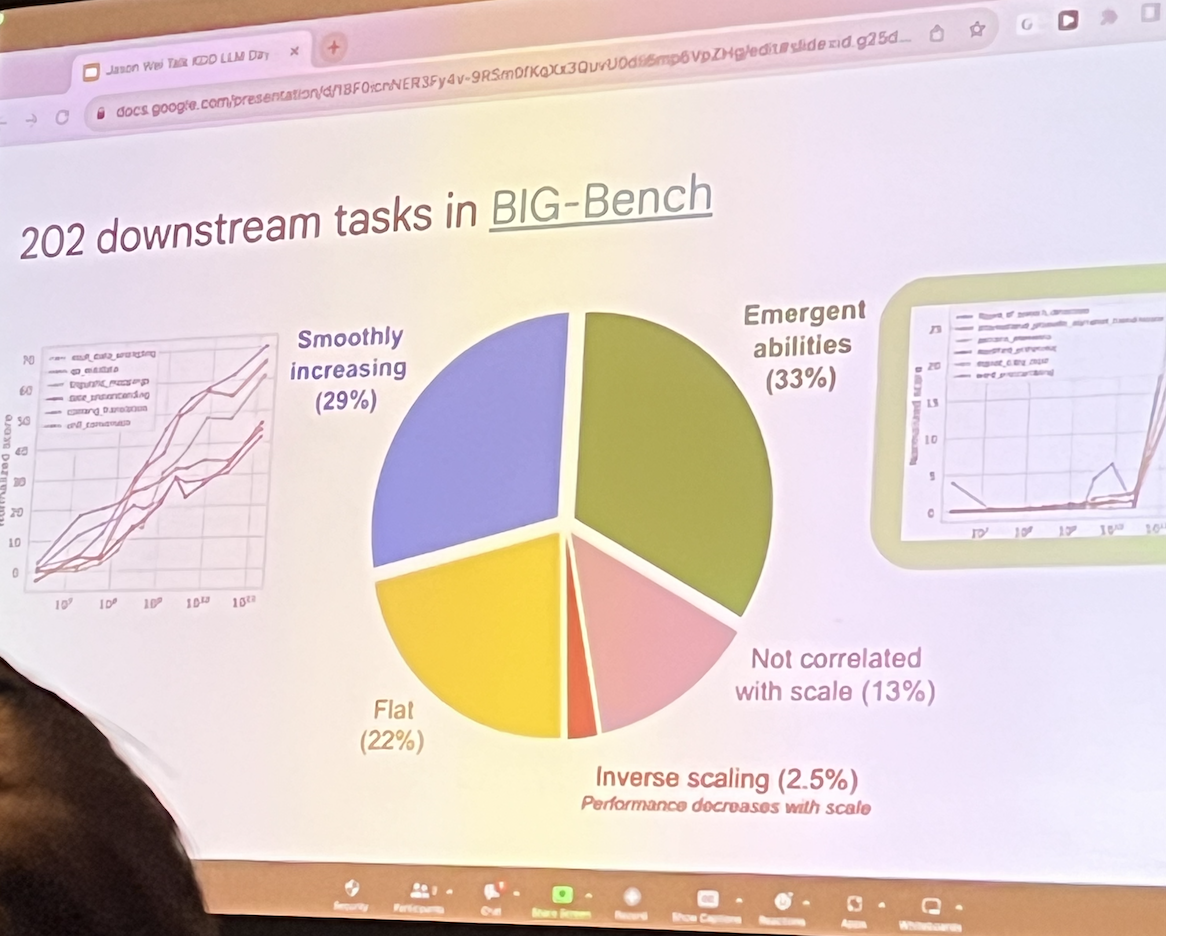
- Emergent Abilities
- Defined as abilities that the model is not explicitly trained for but performs great
- 33% of all tasks are done better by larger models
- Smaller models are great for tasks such as summarisation and search
- Larger models are great for reasoning, solving problems and coding
- What task becomes emergent is an open research question — without trying large models at a full array of QA-pairs, of course
- See Google’s BIG-Bench (creatively named “Beyond the Imitation Game”, largest QA dataset for evals)
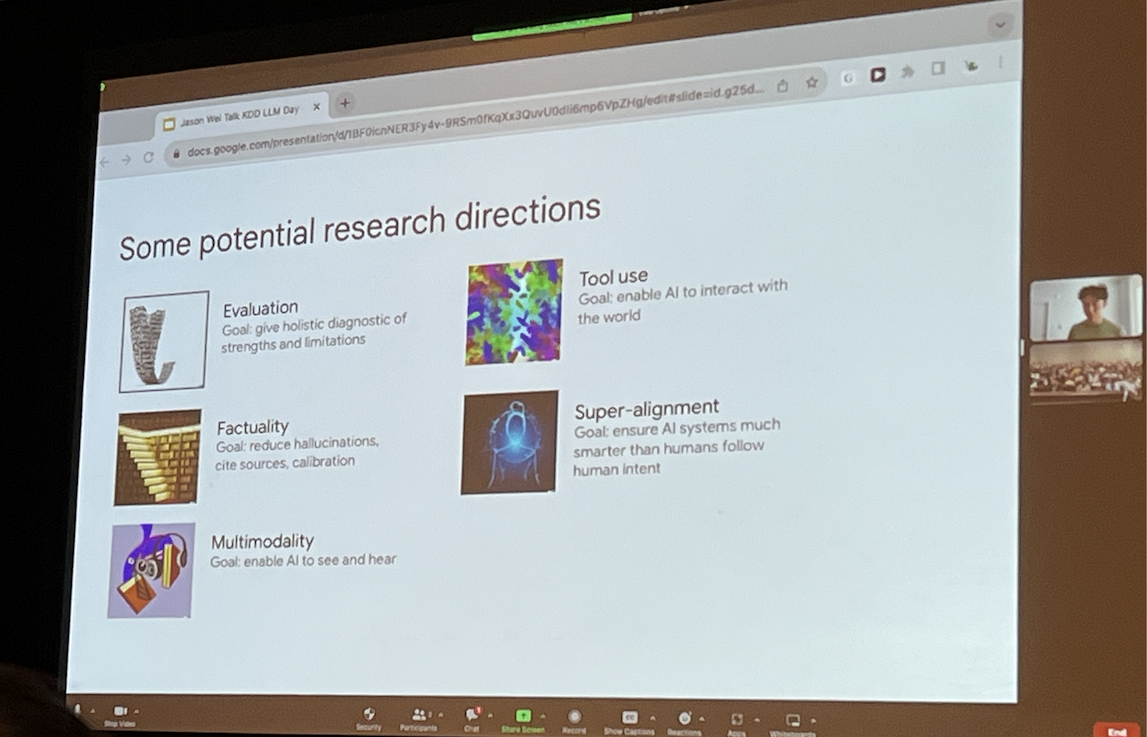
- Benchmarks for QA quickly become outdated. LLMs can beat many creativity tests, turing tests, knowledge tests, reasoning tests, or any such tests that we set up as benchmarks. What is a good benchmark? Does it have to be constantly changing?
- One size doesn’t fit all. Some models are better at some tasks than others. Research should identify which task - which model.
- Reasoning via prompting
- Chain of thought (CoT) reasoning differentiates GPT from previous ML models
- https://arxiv.org/abs/2201.11903
- CoT helps large models, hurts small models (i.e. helps GPT-4, hurts GPT-3.5, ambiguous with GPT-3.5)
- Black magic of ML: hyperparameters; black magic of LLMs: prompting (prompt engineering is thus important)
Applied Data Science Track
BERT4CTR: Using BERT for Predicting Click-through Rates
https://dl.acm.org/doi/10.1145/3580305.3599780
Use fusion algorithms to include the embeddings from LLM into the models
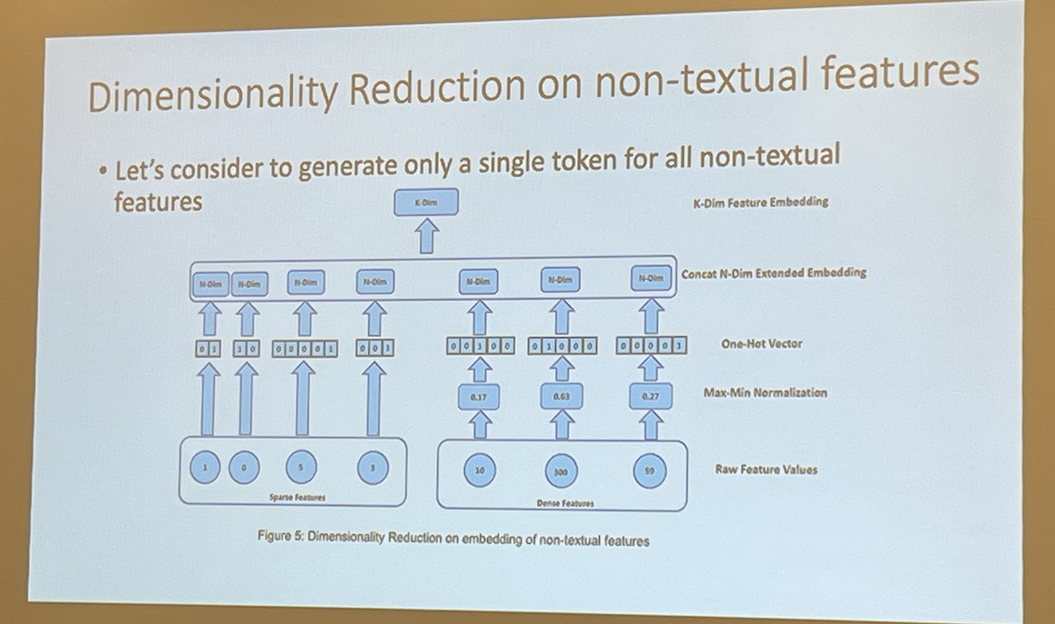
NumBERT: a model to convert non-textual features to textual features
Research by Google et al. using BERT (https://arxiv.org/abs/2010.05345)
This paper is super interesting as they found converting numbers to statements like “This is heavy”, “this is large” was helpful in regression and classification tasks
BERT4CTR takes the first step to convert these non-textual features to textual features and uses them into predicting CTR
All non-text tokens are converted to a single token (how?)
Uses “uni-attention” to create interactions between non-textual and textual features
Dimensionality reduction for embeddings
- My observation from OpenAI’s embeddings was that they were so dense that reduction caused information loss. Maybe not in this case as same numerical information is represented in multiple variables which BERT notices and removes

QUERT: Query Understanding in Travel Domain
https://dl.acm.org/doi/10.1145/3580305.3599891
Using LLMs, understand the search query better to streamline the model for recommendation and search engines
Query has more than intent: it has geography, time, etc.
Phrase permutation is real: “weather new york” and “new york weather now” are likely the same things. LLMs can streamline them into one
From Human Days to Machine Seconds, Iddo Drori
https://arxiv.org/abs/2206.05442
He works at MIT/Columbia and was trying to create questions for MIT’s final exam using LLMs
Questions would be typical questions and then contain the response to that question from an LLM
The task for students was: check if LLMs answer is correct or wrong. If correct, explain why. If wrong, explain why and write the correct response.
Can we teach LLMs to create questions for tests and find answers?
Using LLMs to evaluate responses generated by LLMs
Evaluation of specific responses using meta-questions
Zero-shot, 1-shot, few-shot, chain-of-thought all lead to different levels of accuracy
Zero shot: base LLM
1-shot: use most similar one question from history
N-shot (few-shot): use most similar N questions from history

