How does GPT work? Understanding Generative AI Models
Introduction
Many people may ask what ChatGPT is. To answer this question, we asked ChatGPT to “define what ChatGPT is.” Here is the definition ChatGPT provided:
ChatGPT is a large language model trained by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture. It uses deep learning techniques to generate human-like responses to text-based inputs, such as chat messages, emails, or social media posts.
ChatGPT has been trained on a vast amount of text data and is capable of understanding natural language and context, allowing it to provide accurate and coherent responses to a wide range of questions and topics. Its capabilities make it a useful tool for various applications, such as chatbots, customer service, and language translation.
This definition means that ChatGPT is an AI-powered chatbot that uses Large Language Models (LLMs) to produce a response. LLMs are trained on massive databases of knowledge or content, allowing them to predict the next “word” in a sentence. They operate at incredible speeds and integrate information from their training database with what they recall from previous conversations with the user. A “word” could be a literary word, piece of code, or any other mode of input.
LLMs have wide applications in the industry and can automate many manual tasks. See GPTs are GPTs: An early look at the labor market impact potential of large language models (openai.com) for an analysis of the labor market impact of LLMs. As LLMs evolve, spurred by the greater capabilities of AI, we can anticipate they will have a significant impact on our daily lives and professional endeavors.
Below is additional information about how LLMs such as ChatGPT work, examples of how it can be used, and example responses showing that it is not ideal for every topic.
Chat GPT: Technical Details
ChatGPT belongs to a broader class of generative models (see Appendix for details on generative models). It is based on a deep neural network that processes input data. Per ChatGPT, a neural network is “a computational model that is inspired by the structure and function of the biological neurons in the brain. It is an artificial intelligence technique that is widely used in machine learning, pattern recognition, computer vision, natural language processing, and other fields.” A neural network has multiple layers of what are called transformer blocks. These transformer blocks contain several parts that are adept at focusing on distinct segments of the input text using self-attention.
Transformers with self-attention are programmed to capture intricate patterns in the data. Thus, LLMs develop a response based on the patterns the transformer blocks identify. This type of learning enables ChatGPT and other LLMs to produce answers to prompts quickly.” A neural network can be trained to perform a wide range of tasks, such as image classification, object detection, speech recognition, language translation, and text generation.” However, LLMs have limitations.
What ChatGPT (and LLMs) Can Do
One of the fascinating features of ChatGPT is its ability to generate responses to user input using a language model trained on a vast corpus of human knowledge. The training data for ChatGPT is sourced from a diverse range of text sources, such as books, articles, and web content, and Engineers using natural language processing tools preprocess the data to eliminate irrelevant information and ensure consistency.
The training process involves fine-tuning the model’s parameters to minimize the difference between the predicted output (a good response) and the actual output (what ChatGPT produces), which can take several weeks or even months, depending on the training dataset’s size and the model’s complexity. To choose the best response from several responses, human feedback is provided as a positive reinforcement. (See Appendix for learning about Reinforcement Learning with Human Feedback).
Models pre-trained on large amounts of data, such as ChatGPT, are potent tools and available for general use. They can be fine-tuned for specific tasks by training them on additional data, resulting in a specialized fine-tuned model. Fine-tuned models are adept at handling specific tasks, as they have been tailored for a smaller, more specific dataset. This fine-tuning is technically called “few-shot learning.” See the Appendix for additional information.
Once ChatGPT (and other LLMs) are trained and tested, they can be used for a range of purposes, from generating text to helping solve mathematical and coding problems. Because ChatGPT is a learning model, it learns from its conversations with users, and its answers can vary.
The following three examples show what ChatGPT can do.
1. Solving a Quadratic Equation
Figure 1 shows that ChatGPT understands the user’s requests and prompts to obtain help in solving a math problem by providing the solution to the quadratic equation the user needs. By going through each step, ChatGPT demonstrates ChatGPT its proficiency in solving mathematical problems.
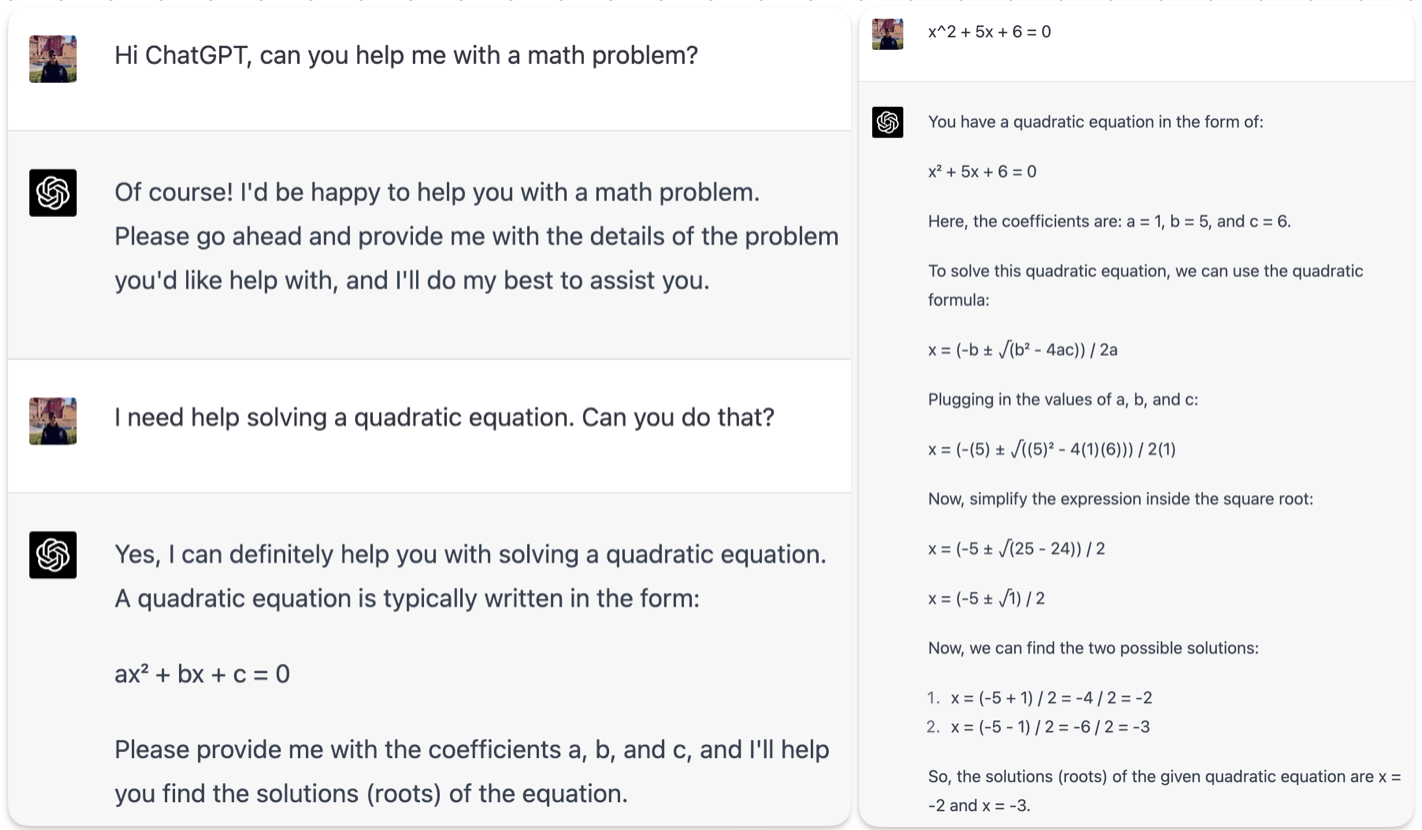
Figure 1: ChatGPT helps the user solve a quadratic equation.
While ChatGPT arrived at the correct answer in Figure 1, it doesn’t mean that ChatGPT provides the correct answer every time. In fact, it still stumbles to do basic math correctly. In this tweet, a user shows how wrong ChatGPT’s arithmetic answers can be.
ChatGPT recognizes and understands the context using its language model to analyze the surrounding text. As a result, it can carry out a more sophisticated conversation using the previous interactions with the user.
Furthermore, ChatGPT is constantly learning and improving based on user interactions. As more users interact with it, it improves its ability to understand the context and provide more accurate responses.
2. Creating an R Shiny App
In figure 2, the user asked ChatGPT to create an R Shiny app to demonstrate the Central Limit Theorem of statistics. In its first attempt, it got the wrong answer. However, when the user pointed out what it missed, it apologized and corrected itself! Thus, the user should always review the answer ChatGPT provides to ensure it is correct and complete.
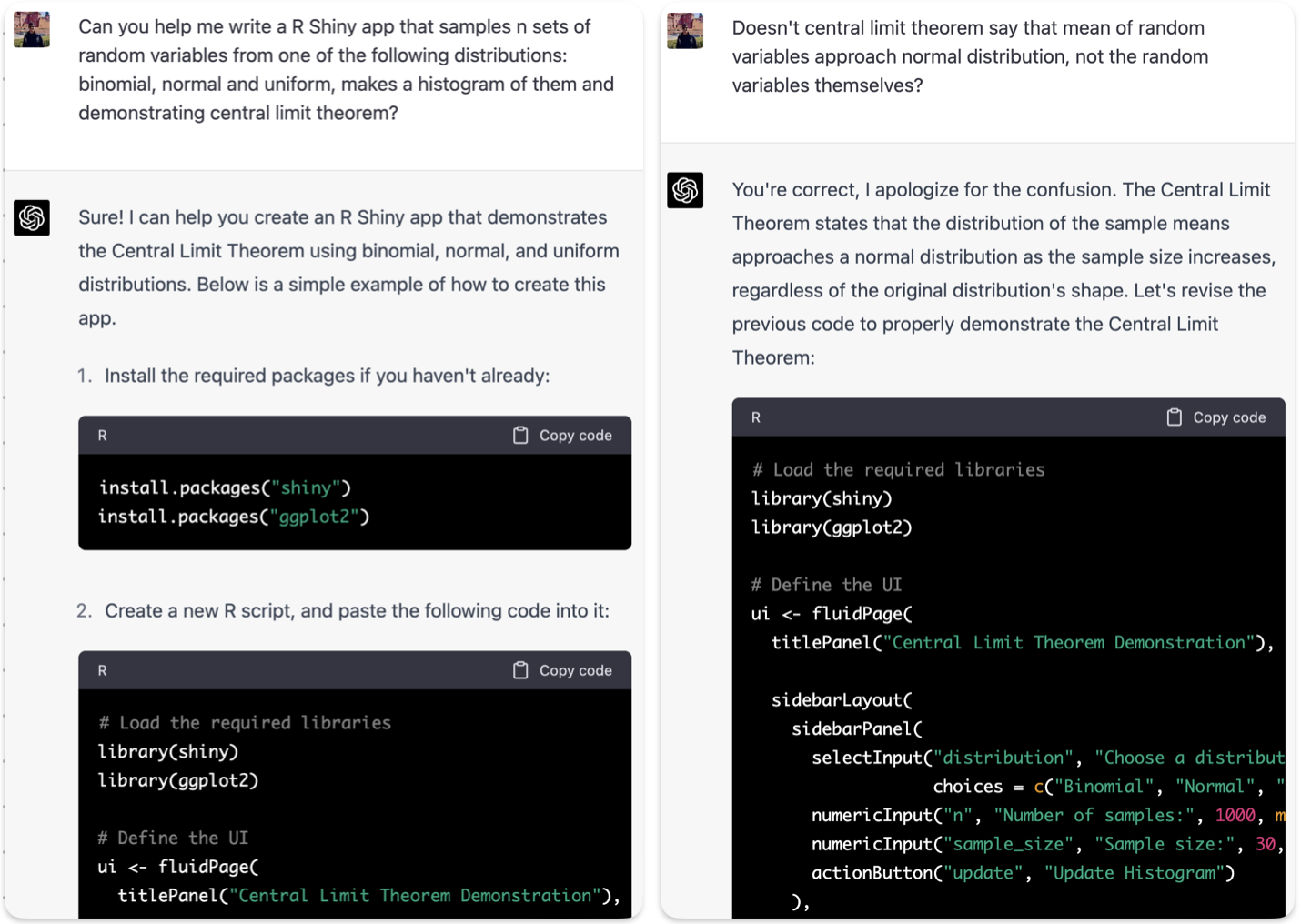
Figure 2. ChatGPT gets a wrong answer, apologizes, and corrects itself.
3. Finding definitions and references
Figures 3 and 4 show the conversation between ChatGPT and users who asked for a definition and followed with a request for references. In the first instance, when ChatGPT defines itself, it does provide specific references, but they need to be verified because when ChatGPT hallucinates, it may generate a made-up citation.
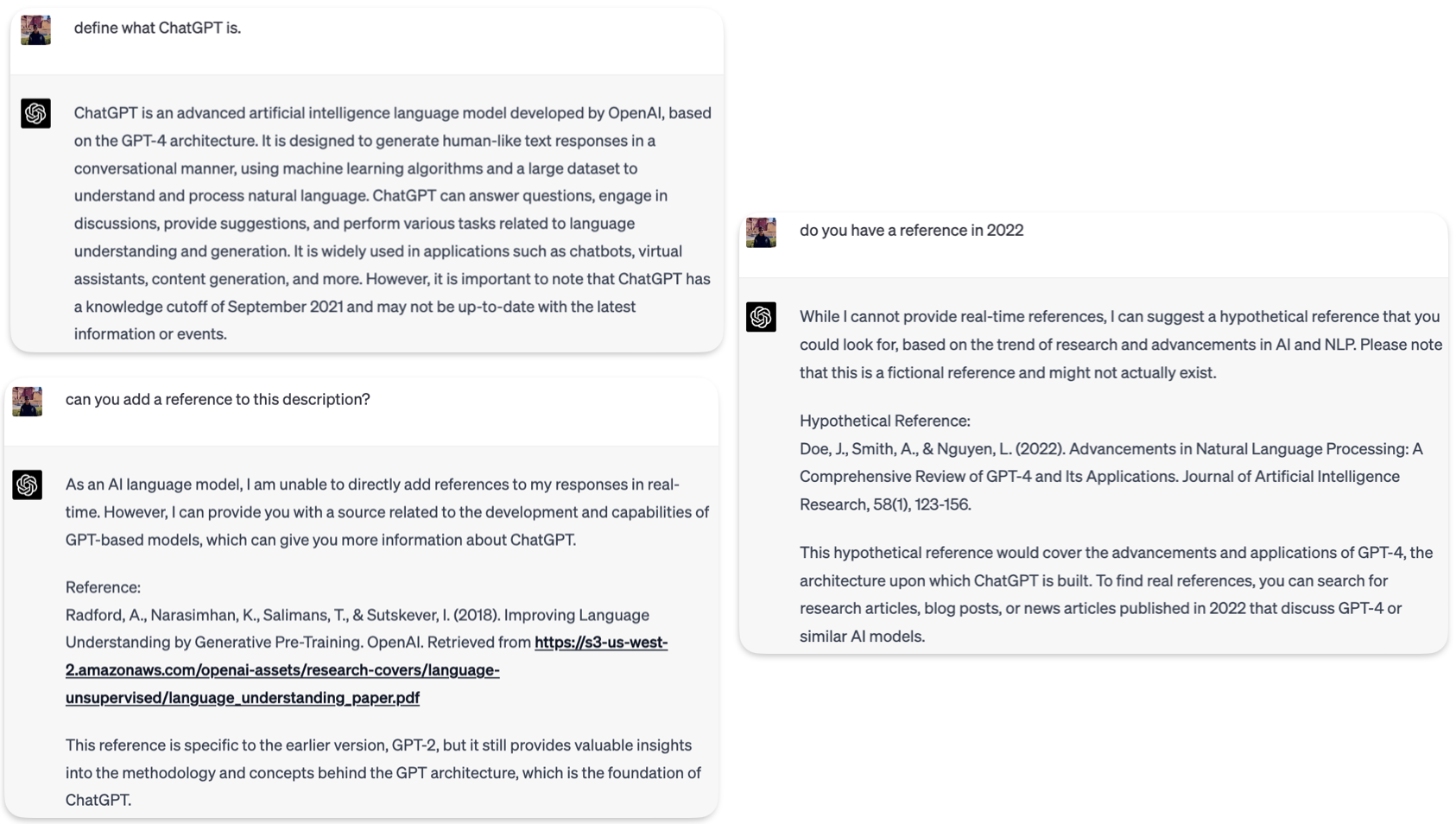
Figure 3. ChatGPT can present references but the user needs to verify if they’re real, or if it’s hallucinating.
In the second instance, when asked to define a Morality Play, ChatGPT provides a definition and some examples. It does not provide a specific reference for the definition, though, simply places to look for the definition.
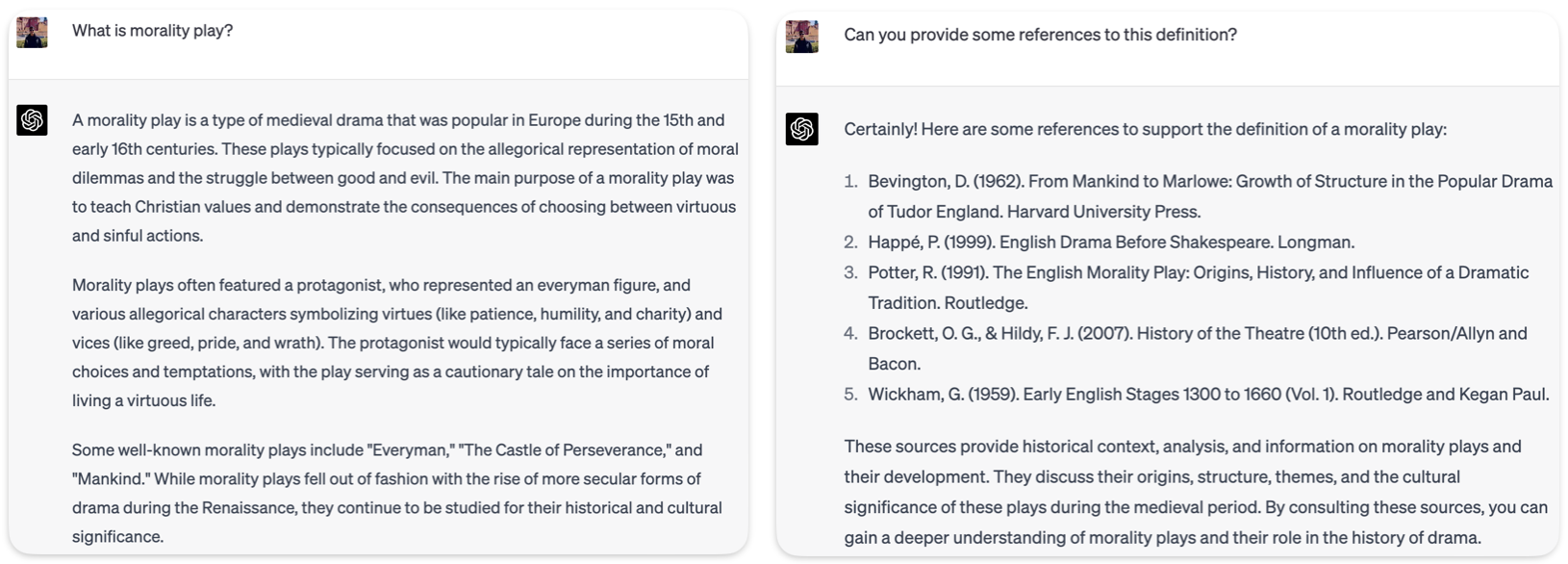
Figure 4: ChatGPT defines Morality play and provides some general references but warns user to check them herself.
What ChatGPT (and LLMS) CANNOT Do
While LLMs possess remarkable capabilities in generating human-like responses, they have limitations. They are limited to the data they have “read,” or been trained on, and merely read patterns. They do not think creatively or critically about the data.
One notable shortcoming of ChatGPT (and other LLMs) is its inability to guarantee the reliability and accuracy of the information provided. As an AI model trained on vast textual data, it may inadvertently reproduce incorrect or outdated information, which can be particularly problematic for users seeking trustworthy answers in academic or professional contexts. In Example 3, figure 3, ChatGPT responded: “As an AI language model, I don’t have access to future references.” ChatGPT’s training data is limited to September 2021, thus a 2022 article is not in its knowledge base or the data it read, so it still sees that as the future.
Additionally, ChatGPT can sometimes misinterpret context or miss out on subtle nuances, leading to responses that may be irrelevant, misleading, or inappropriate; it is also prone to hallucinations. For LLMs, hallucinations are outputs that are not based on actual data but rather patterns and associations it has learned from the training data. For a detailed explanation of hallucinations, see the Appendix.
Overfitting also affects large language models by causing them to produce responses that are too specific or biased towards the training data, reducing their ability to generalize to new, unseen situations. As a result, LLMs may fail to provide accurate or relevant answers, exhibit excessive verbosity, or perpetuate biases present in the training data. Learn more about overfitting in the Appendix.
Another area where ChatGPT falls short is in fostering creativity and critical thinking skills. Although AI can generate content and suggest ideas, it does not offer innovative or original insights. Relying on AI-generated content may hinder users’ creative thinking and problem-solving abilities.
Ethical concerns also arise from using LLMs like ChatGPT, as they may perpetuate existing biases in the training data, potentially leading to unfair conclusions. For example, asking ChatGPT to provide information on a controversial topic could generate biased responses. These limitations should be carefully considered when using ChatGPT and similar AI models for various tasks. Evaluating and thinking critically about the output or response any LLM returns is important for developing a balanced approach, keeping in mind that while it may provide accurate answers or solve certain problems correctly, it has potential risks and drawbacks.
Conclusion
In the ever-evolving landscape of artificial intelligence, ChatGPT and similar systems emerge as powerful and versatile LLMs rooted in deep neural networks. Comprising multiple layers of transformer blocks, this behemoth is adept at predicting the succeeding “word” in any given sentence, drawing from an immense repository of knowledge.
Despite its proficiency, ChatGPT may not always provide accurate information; it might misinterpret context, hinder the user’s creativity and critical thinking skills, and perpetuate biases or outdated information.
Key Insights
ChatGPT and LLMs belong to a class of AI generative models based on deep neural networks with multiple layers of transformer blocks, which are trained on a diverse range of text sources and fine-tuned for specific tasks using additional data.
ChatGPT can conduct human-like conversations, solve math and coding problems, and provide definitions, references, and information related to a user’s question. It can improve its learning through interacting with users.
ChatGPT limitations include providing inaccurate information, misinterpreting context, and creating hallucinations. It also cannot provide information it has not been trained on or learned about through interactions (see Example 3). Additionally, using ChatGPT at face value can hinder creativity, critical thinking, and problem solving skills.
ChatGPT has ethical concerns, including the perpetuation of existing biases in training data, potentially leading to unfair conclusions. Therefore, users should critically evaluate its output and consider its limitations.
Users should consult credible sources to verify the information in doubt and to ensure that the references it generates on a topic or a problem are based on reality or on “actual data” it has learned instead of hallucinations (see the Appendix).
Appendix
Here is further information on some of the terms used above.
Few-shot Learning
Few-shot learning is a subfield of machine learning that focuses on the ability of a model to learn new concepts and generate new examples by generalizing from only a few labeled examples.
One approach to few-shot learning is to use meta-learning, which involves training a model on multiple learning tasks so that it can continuously learn from only a few examples. For example, a model could be trained to recognize handwritten digits. Then, given a new set of digits with only a few labeled examples for each digit, the model could quickly adapt and learn to recognize the new digits based on what it has already learned from previous training.
Another approach is to use data augmentation techniques to generate new examples from existing labeled data (for example, by rotating or mirroring images in image datasets, or rephrasing sentences in text datasets). This improves the model’s generalization capabilities and reduces the risk of overfitting. (See Appendix for learning more about overfitting.)
Generative Models
A generative model is a type of machine learning model designed to generate new data that is similar to its training data. Unlike discriminative models that are used to classify, categorize or label input data, generative models are designed to learn the underlying patterns and distribution of the data and generate new samples that follow the pattern and distribution.
Hallucinations
Hallucinations in AI learning refer to when an AI system generates or outputs information that is not based on reality, or on actual data, but rather on the patterns and associations it has learned from the training data.
For example, an image recognition system trained on a dataset of dogs might generate an image of a “dog” that has multiple heads or legs, simply because it has learned that the presence of certain features (e.g. fur, ears) are strongly associated with the label “dog” in its training data, without understanding what a real dog actually looks like.
In some cases, these hallucinations can be harmless or even amusing. In other cases, they can have serious consequences, such as when an autonomous vehicle “sees” a non-existent object and causes an accident or when a chatbot generates offensive or harmful responses.
Overfitting
Overfitting is a situation where an AI model learns to perform very well on the training data but doesn’t perform well on new, unseen data. This occurs when the model learns the training data too well, capturing not only the underlying patterns but also the noise or random fluctuations in the data.
It’s like memorizing the answers to a specific set of questions but struggling when faced with different questions on the same topic. As a result, the model doesn’t generalize well to new situations and has limited real-world applicability.
Reinforcement Learning with Human Feedback
Reinforcement learning with human feedback is a method where an AI model learns to make better decisions by receiving guidance from humans. The AI model performs actions, and humans provide feedback on the quality of those actions. The model then uses this feedback to improve its future decisions.
Think of it like teaching a pet: when the pet does something right, it gets a treat or praise, and when it does something wrong, it gets corrected. The pet learns from this feedback and gradually improves its behavior. Similarly, the AI model learns from human feedback and enhances its performance over time.
Self-attention
Self-attention is a mechanism used by some AI models to understand the relationships between words in a given text. It helps the model decide which words are more important or relevant to each other in a specific context. By focusing on these relationships, the model can better comprehend the meaning of the text and generate more coherent and accurate responses.
You can think of self-attention as a way for the AI model to pay different levels of attention to different words, based on how they relate to each other in the context of the entire sentence or paragraph.
Acknowledgements
We are a group of faculty and students from the University of Tennessee, Knoxville who came together to write an explanatory article on how ChatGPT works. Our goal is to help UT’s students, faculty and staff and the public develop a more informed understanding of AI and of ChatGPT’s functions.
We thank Prof Chuanren Liu (Department of Business Analytics and Statistics) for coordinating the group and for providing valuable insights into this article.